Analyzing large files locally in seconds with DuckDB and DataGrip

If you have ever received a huge csv file that you had to analyze or just quickly wanted to peek into to check it’s structure your go-to tool is usually pandas and a small Python script.
But if you are like me and always have DataGrip (or any other JDBC-compatible SQL IDE) open and for quick routine checks like this prefer SQL compared to Python, this guide is for you!
If you haven’t head about the two pieces of tech we’ll use here’s a short description of each:
DuckDB is an in-process. SQL OLAP database management system · All the benefits of a database, none of the hassle.
DataGrip is a database management environment for developers. It is designed to query, create, and manage databases. Databases can work locally, on a server, or in the cloud.
Set up the environment
- Download the DuckDB JDBC driver from Maven.
- In DataGrip create a new Driver configuration using the download jar file.
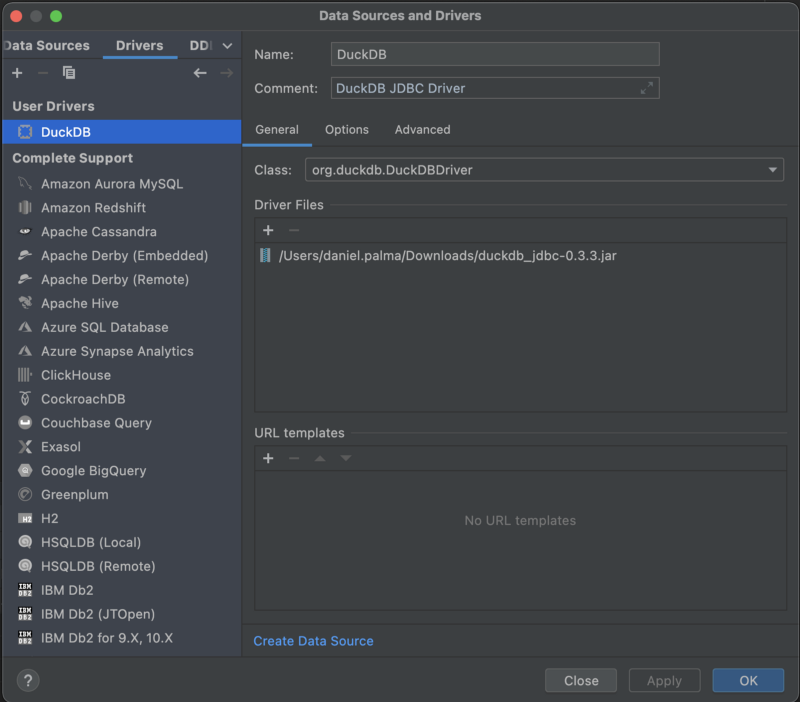
3. Create a new Data Source, the connection URL should be just jdbc:duckdb: as shown in the screenshot below.
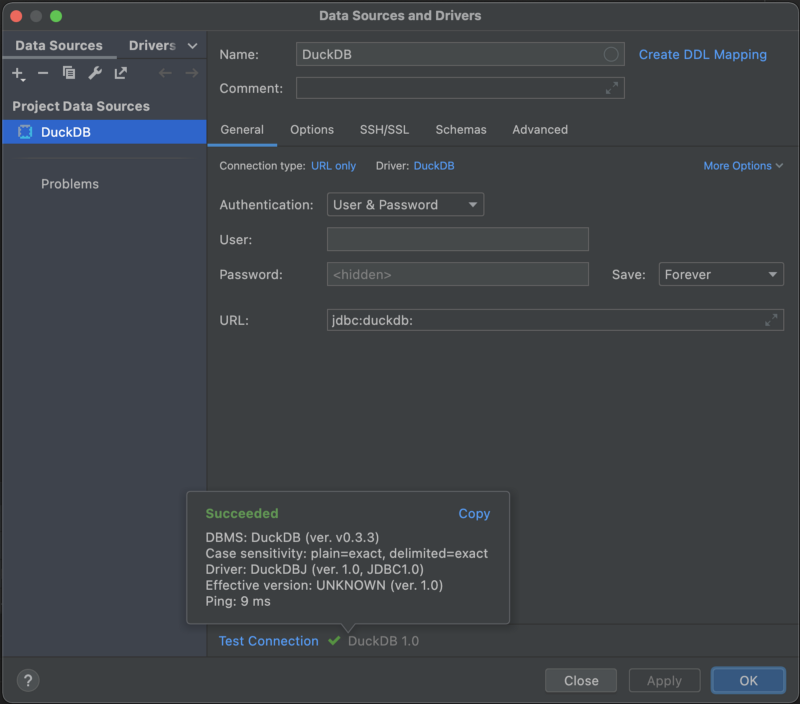
4. Generate a bigger .csv file to showcase the functionality.hexdump -v -e '5/1 "%02x""\n"' /dev/urandom |
awk -v OFS=',' '
NR == 1 { print "employee", "department", "salary" }
{ print substr($0, 1, 8), substr($0, 9, 2), int(NR * rand()) }' |
head -n "$1" > data.csv
Using this shell script we can generate a csv with 10000000 lines easily.~/duckdb-datagrip/generate-csv.sh 10000000~/duckdb-datagrip ❯ ls -lah
drwxr-xr-x 4 daniel.palma staff 128B May 28 08:47 .
drwxr-xr-x 8 daniel.palma staff 256B May 28 08:33 ..
-rw-r--r-- 1 daniel.palma staff 187M May 28 09:16 data.csv
-rwxr--r-- 1 daniel.palma staff 217B May 28 09:14 generate-csv.sh
As you can see we generated an almost 200MB .csv file in a second (at least on my machine). This is a fairly realistic use case (although a bit bigger than usual).
5. Let’s get to querying!select * from '/path/to/data.csv';
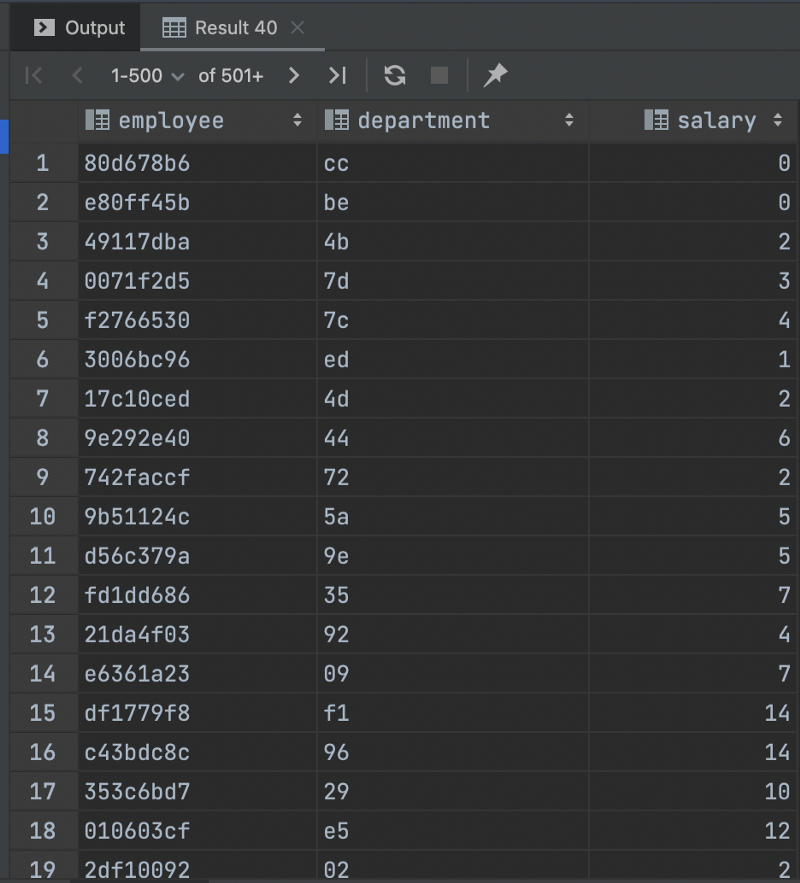
Reading the whole 200MB file took less than a second and the types have been parsed perfectly by DuckDB automatically.
Let’s see how’s the performance with some basic analytical queries.> select count(*) from '/path/to/data.csv'1 row retrieved starting from 1 in 683 ms (execution: 663 ms, fetching: 20 ms)
Not bad! What about a window function? Let’s try to find the employees in each department with the second highest salary.> WITH ranking AS
(SELECT *, RANK() OVER (PARTITION BY employee, department ORDER BY salary Desc) AS rnk
FROM '/Users/daniel.palma/Personal/duckdb-datagrip/data.csv')
SELECT employee, department, salary
FROM ranking
WHERE rnk = 252 rows retrieved starting from 1 in 16 s 557 ms (execution: 16 s 544 ms, fetching: 13 ms)
Alright that took a bit longer, but I’m still comfortable with this.
Conclusion
This is just scratching the surface of what DuckDB can do, make sure to check it out!
Member discussion