Dremel: How Google Reinvented SQL for Petabyte-Scale Analytics

The Problem: Why Was Dremel Necessary?
Before 2010, querying large-scale datasets at Google (and across the industry) was slow. Engineers had two main options:
- Traditional Databases: SQL-based systems were great for structured queries but couldn’t scale to petabyte-sized datasets.
- MapReduce: Distributed batch processing enabled large-scale analytics but required minutes or hours to complete queries, making real-time analysis impossible.
Google needed a system that combined the scalability of MapReduce with the speed of traditional databases—something that could scan trillions of rows in seconds. That system was Dremel, and it fundamentally changed the way we query data at scale.
How Dremel Works: Key Innovations
Dremel introduced three key innovations that enabled interactive queries on web-scale datasets:
1. Columnar Storage for Nested Data
Dremel doesn’t store data row-by-row like traditional databases. Instead, it stores each field separately in a columnar format—even for deeply nested structures.
Why is this faster?
- Only the relevant columns are read from disk, reducing I/O.
- Compression is more efficient because similar values are stored together.
- Query execution benefits from CPU cache locality.
How does it handle nested data? Dremel introduced Repetition and Definition Levels to maintain relationships between nested fields in a columnar format. This enables fast, schema-aware queries without the need for costly joins.
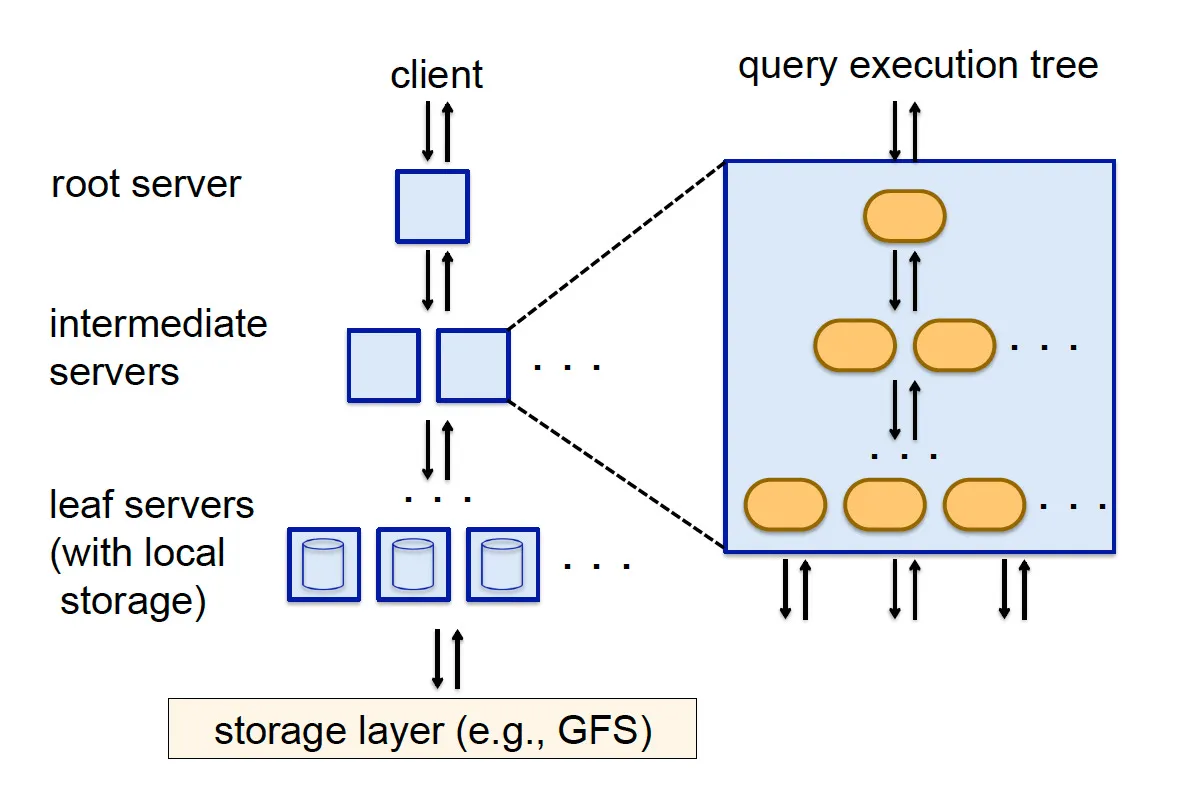
2. Multi-Level Execution Tree
Dremel borrows from Google’s web search infrastructure to distribute queries across thousands of nodes using a serving tree architecture.
How does it work?
- The root node receives the query and distributes it to intermediate nodes.
- Intermediate nodes process and aggregate partial results.
- Leaf nodes scan data in parallel and push results up the tree.
- The final result is assembled and returned to the user.
This massively parallel execution ensures that queries over trillions of rows complete in seconds.
3. SQL-Like Query Execution Without MapReduce
Unlike Hive and Pig, which translate queries into MapReduce jobs, Dremel executes SQL queries natively, avoiding the overhead of batch processing.
Key features of Dremel’s query engine:
- SQL syntax: Supports aggregation, filtering, and complex queries.
- Within-record aggregation: Operates efficiently on nested data.
- Top-K queries & approximations: Enables fast ranking and distinct counts.
How Dremel Changed Data Engineering
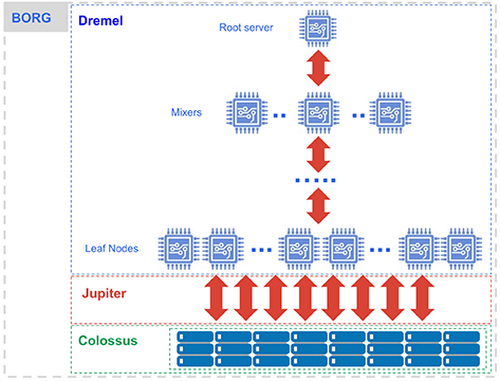
Dremel became the foundation for Google BigQuery, a fully managed analytics database that powers thousands of companies today. The same principles have influenced Apache Parquet, Snowflake, and Redshift Spectrum.
Performance Breakdown
Let’s compare query execution time for a 1PB dataset across different architectures:
| System | Execution Time |
|---|---|
| MapReduce | Hours |
| Hive / SparkSQL | Minutes |
| Dremel / BigQuery | Seconds |
For modern data engineers, understanding columnar storage, distributed execution trees, and native SQL processing is key to optimizing queries on cloud-scale data warehouses.
Hands-on: Querying Nested Data in BigQuery (Dremel’s Successor)
Dremel’s ideas are implemented in Google BigQuery. Here’s how you can run a nested data query today:
SELECT document_id, COUNT(language.code) AS language_count
FROM dataset.web_documents
WHERE REGEXP_CONTAINS(url, r'^https')
GROUP BY document_id;
How is this optimized?
- Columnar storage ensures only the
language.codecolumn is scanned. - The serving tree distributes aggregation across multiple nodes.
- The engine executes SQL natively without translating it to MapReduce.
Lessons for Modern Data Engineers
- Optimize for columnar execution – Always select only the necessary columns to minimize I/O.
- Understand nested data storage – Learn how Repetition and Definition Levels impact performance in Parquet/BigQuery.
- Leverage parallel execution – Choose the right tool (batch vs. interactive querying) based on your latency requirements.
Dremel is a great piece of technology that is still influencing the data space. If you're interested in the technical details, read the paper here.
Member discussion