Streaming Data Lakehouse Foundations: Powering Real-Time Insights with Kafka, Flink, and Iceberg
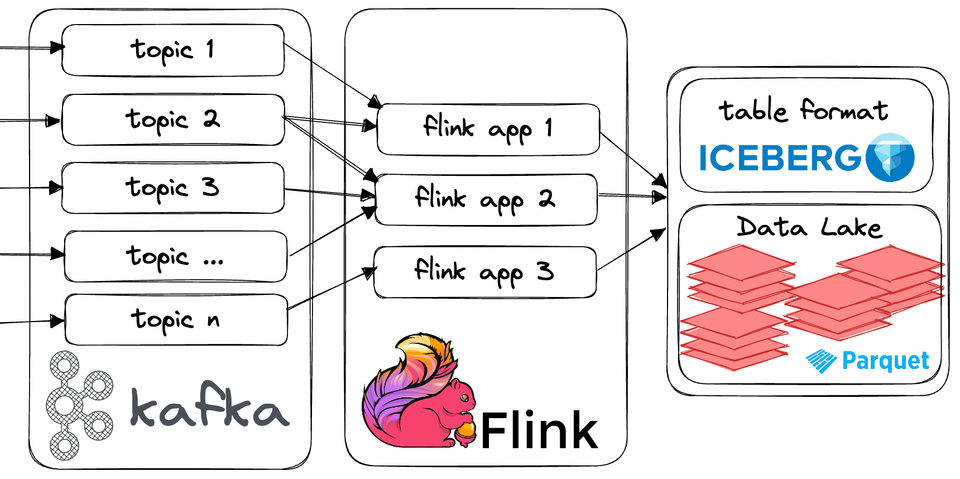
In the fast-paced world of data, the need for real-time insights has never been more critical. Enter the streaming data lake, a dynamic reservoir that harnesses the power of continuous data streams. To build this foundation, we turn to three formidable technologies: Kafka, Flink, and Iceberg. These three champions seamlessly integrate to create a data processing powerhouse, enabling organizations to unlock the true potential of their streaming data. Get ready to dive into the world of streaming data lakes, where real-time analytics reign supreme!
In this article, we'll go over these concepts, technologies in a bit more detail and take a look at a locally reproducible, minimal implementation of the stack.
Building Blocks
Alright, with that short rant over, let's go over our architectures main building blocks in a little bit more details and see an implementation example as well.
Data Lake

A data lake is a central repository that stores structured, semi-structured, and unstructured data at any scale. Unlike traditional data warehousing approaches, data lakes allow organizations to store raw data without upfront transformation, providing the flexibility to analyze data in its native format. Data lakes provide a foundation for various data processing and analytics workflows, including batch processing and real-time streaming analytics.
For a quick getting started guide on implementing a data lake at home, check out my other article.
In our little local data lakehouse, we'll implement the data lake using MinIO, an amazing open-source object storage (I rave about it more here.)
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- "9001:9001"
- "9000:9000"
command: [ "server", "/data", "--console-address", ":9001" ]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"The minio service starts the actual object storage process, while the mc one runs once, creating our bucket which will serve as the main storage entry point for our lake.
Apache Kafka
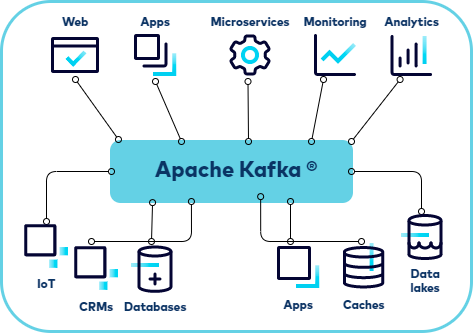
Apache Kafka is a distributed streaming platform that provides a publish-subscribe model for real-time data streaming. It is designed to handle high volumes of data and offers fault tolerance, scalability, and durability. Kafka allows producers to publish data to topics, while consumers subscribe to these topics to process the data in real time. Kafka's architecture ensures data replication and fault tolerance, making it highly reliable for mission-critical applications.
Kafka's integration with data lakes is crucial in building a streaming data processing pipeline. It acts as a reliable and scalable ingestion layer that can handle high-throughput data streams. Kafka connectors enable seamless integration with various data sources, such as databases, message queues, and event streams. By leveraging Kafka's distributed nature, data can be efficiently streamed into the data lake for further processing and analysis.
For our example, we can use the Confluent-provided images:
broker:
image: confluentinc/cp-kafka:7.4.0
hostname: broker
container_name: broker
networks:
iceberg_net:
depends_on:
- controller
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@controller:9093'
KAFKA_LISTENERS: 'PLAINTEXT://broker:29092,PLAINTEXT_HOST://0.0.0.0:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
# Replace CLUSTER_ID with a unique base64 UUID using "bin/kafka-storage.sh random-uuid"
# See https://docs.confluent.io/kafka/operations-tools/kafka-tools.html#kafka-storage-sh
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qk'
controller:
image: confluentinc/cp-kafka:7.4.0
hostname: controller
container_name: controller
networks:
iceberg_net:
ports:
- "9093:9093"
- "9102:9102"
environment:
KAFKA_NODE_ID: 2
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9102
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'controller'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@controller:9093'
KAFKA_LISTENERS: 'CONTROLLER://controller:9093'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-controller-logs'
# Replace CLUSTER_ID with a unique base64 UUID using "bin/kafka-storage.sh random-uuid"
# See https://docs.confluent.io/kafka/operations-tools/kafka-tools.html#kafka-storage-sh
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qk'
control-center:
image: confluentinc/cp-enterprise-control-center:7.4.0
hostname: control-center
container_name: control-center
networks:
iceberg_net:
depends_on:
- broker
- controller
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021Apache Flink
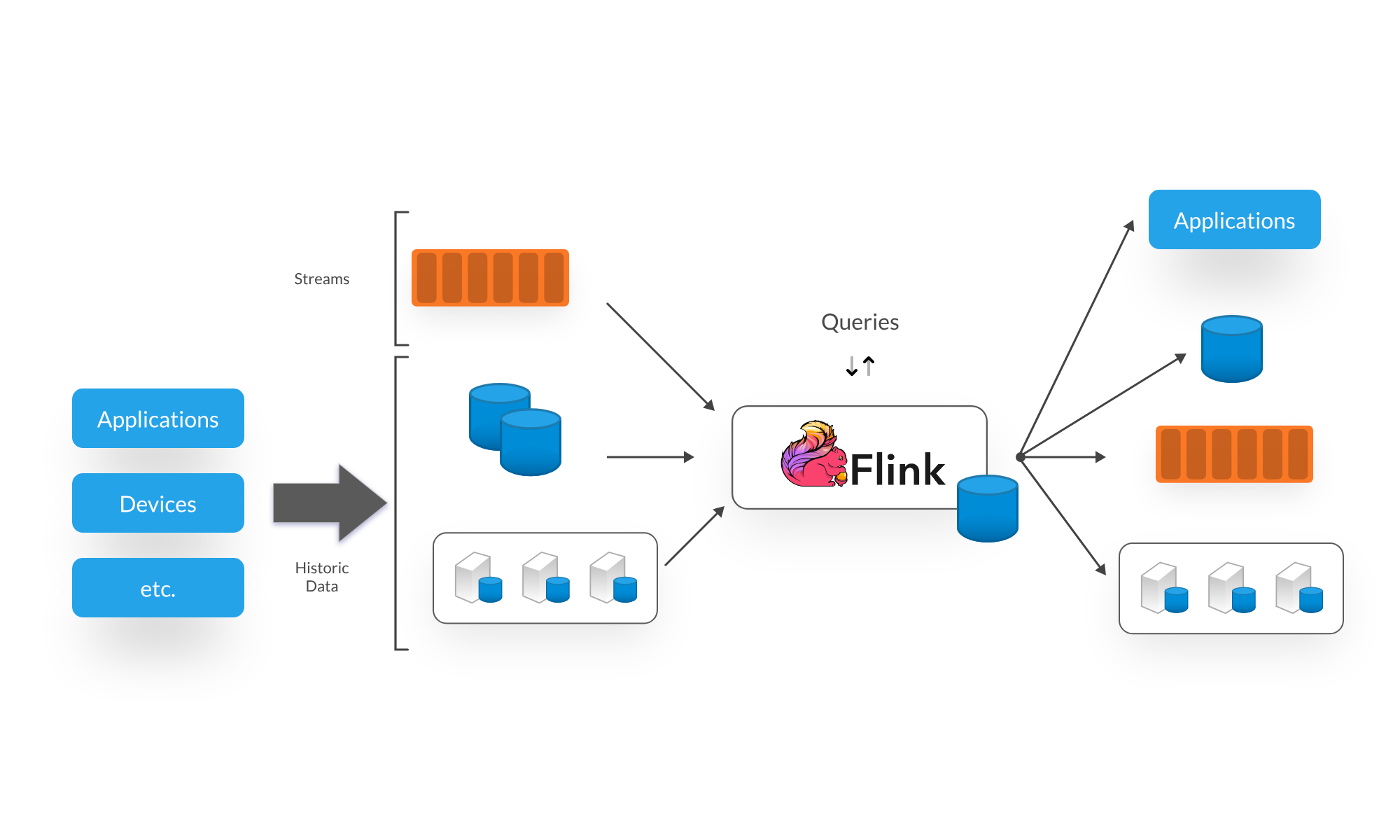
Apache Flink is a powerful stream processing framework that enables real-time data processing and analytics. It provides a unified programming model for both batch and stream processing, making it an ideal choice for building end-to-end streaming data pipelines. Flink supports exactly-once semantics, fault-tolerance, and low-latency processing, making it suitable for use cases that require real-time insights.
Flink seamlessly integrates with Kafka through its official connectors, allowing for data ingestion from Kafka topics and processing using Flink's operators. Flink's windowing capabilities enable time-based aggregations and event-time processing, making it easy to derive valuable insights from streaming data. With Flink's support for stateful processing, complex event processing, and machine learning libraries, organizations can build sophisticated streaming applications on top of their data lakes.
Flink is cool. Complex, but cool. If you want to get involved in streaming in any form make sure to dedicate some time to grok its architecture and philosophy, at least on a high level.
We'll configure Flink to be run in Session mode, with two services, a jobmanager and a taskmanager.
The jobmanager has a number of responsibilities related to coordinating the distributed execution of Flink Applications: it decides when to schedule the next task (or set of tasks), reacts to finished tasks or execution failures, coordinates checkpoints, and coordinates recovery on failures, among others.
The taskmanagers (also called workers) execute the tasks of a dataflow, and buffer and exchange the data streams.
flink-jobmanager:
image: flink:1.16.2-scala_2.12-java11
container_name: flink-jobmanager
ports:
- "8081:8081"
command: jobmanager
networks:
iceberg_net:
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
flink-taskmanager:
image: flink:1.16.2-scala_2.12-java11
container_name: flink-taskmanager
depends_on:
- flink-jobmanager
command: taskmanager
networks:
iceberg_net:
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1Nice! Almost there, the only thing left to do is to generate some data and glue everything together to see it in action!
I'll use a small data generation script and include it in the docker-compose file for easier management.
datagen:
build: datagen
container_name: datagen
networks:
iceberg_net:
depends_on:
- brokerAs for the Flink application, let's write a small job in Java. As our data generation script is going to generate clickstream data in the following format:
{
"timestamp": "2020-11-16 22:59:59",
"event": "view_item",
"user_id": "user1",
"site_id": "wj32-gao1-4w1o-iqp4",
"url": "https://www.example.com/item/1",
"on_site_seconds": 55,
"viewed_percent": 30
}We'll create a basic Flink app that reads and parses the records coming from Kafka and publishes them into an Iceberg table.
public class ClickStreamStream {
private static final Logger LOGGER = LoggerFactory.getLogger(ClickStreamStream.class);
public static void main(String[] args) throws Exception {
ParameterTool parameters = ParameterTool.fromArgs(args);
Configuration hadoopConf = new Configuration();
Map<String, String> catalogProperties = new HashMap<>();
catalogProperties.put("uri", parameters.get("uri", "http://rest:8181"));
catalogProperties.put("io-impl", parameters.get("io-impl", "org.apache.iceberg.aws.s3.S3FileIO"));
catalogProperties.put("warehouse", parameters.get("warehouse", "s3://warehouse/wh/"));
catalogProperties.put("s3.endpoint", parameters.get("s3-endpoint", "http://minio:9000"));
CatalogLoader catalogLoader = CatalogLoader.custom(
"demo",
catalogProperties,
hadoopConf,
parameters.get("catalog-impl", "org.apache.iceberg.rest.RESTCatalog"));
Schema schema = new Schema(
Types.NestedField.optional(1, "timestamp", Types.StringType.get()),
Types.NestedField.optional(2, "event", Types.StringType.get()),
Types.NestedField.optional(3, "user_id", Types.StringType.get()),
Types.NestedField.optional(4, "site_id", Types.StringType.get()),
Types.NestedField.optional(5, "url", Types.StringType.get()),
Types.NestedField.optional(6, "on_site_seconds", Types.IntegerType.get()),
Types.NestedField.optional(7, "viewed_percent", Types.IntegerType.get())
);
Catalog catalog = catalogLoader.loadCatalog();
TableIdentifier outputTable = TableIdentifier.of(
"test",
"clickstream");
if (!catalog.tableExists(outputTable)) {
catalog.createTable(outputTable, schema, PartitionSpec.unpartitioned());
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(Integer.parseInt(parameters.get("checkpoint", "10000")));
KafkaSource<Click> source = KafkaSource.<Click>builder()
.setBootstrapServers("broker:29092")
.setTopics("clickstream")
.setGroupId("clickstream-flink-consumer-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new ClickDeserializationSchema())
.build();
DataStreamSource<Click> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
DataStream<Row> streamRow = stream.map(Click::toRow);
// transform the data here!
FlinkSink.forRow(streamRow, FlinkSchemaUtil.toSchema(schema))
.tableLoader(TableLoader.fromCatalog(catalogLoader, outputTable))
.toBranch(parameters.get("branch", "main"))
.distributionMode(DistributionMode.HASH)
.writeParallelism(2)
.append();
env.execute();
}
}Iceberg and Table Formats
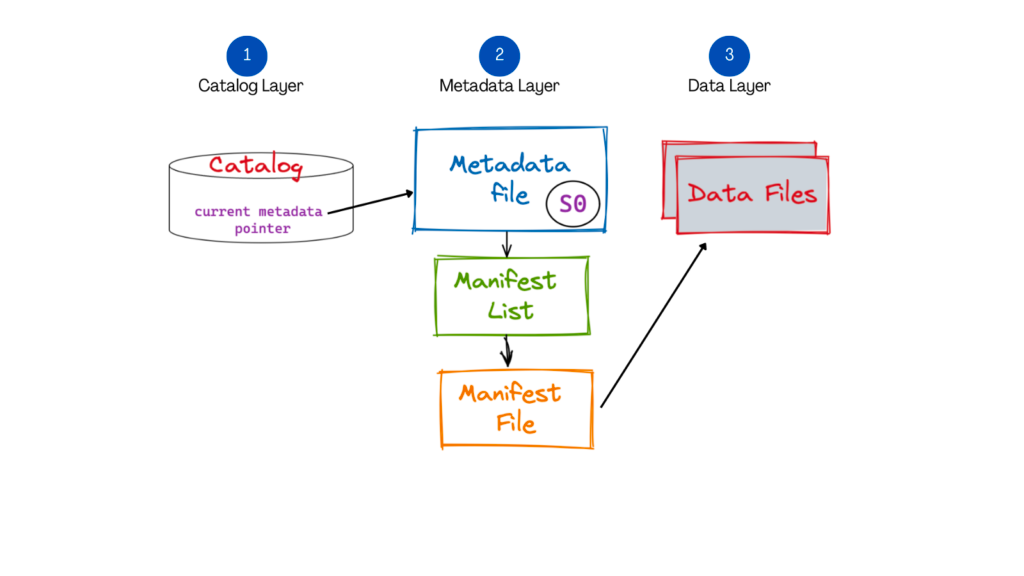
When dealing with large-scale data lakes, managing data efficiently becomes crucial. This is where Iceberg, an open-source table format, plays a significant role. Iceberg provides a scalable and transactional approach to managing large datasets in a data lake environment. It addresses challenges related to data versioning, schema evolution, and data governance.
Iceberg's table format organizes data into smaller, immutable files, known as data files, persisted in parquet format. It supports fine-grained transactional operations, enabling atomic commits and isolation guarantees. Iceberg also introduces the concept of metadata files, which store schema and partition information, providing a unified view of the data. The separation of metadata and data files allows for efficient schema evolution without expensive data rewrites.
The combination of Kafka, Flink, and Iceberg

By combining Kafka, Flink, and Iceberg, organizations can build a robust and scalable streaming data lake infrastructure. Kafka serves as the backbone for ingesting real-time data streams, ensuring fault-tolerant and scalable data ingestion. Flink, on the other hand, enables complex stream processing and analytics, allowing organizations to derive meaningful insights from the data in real time. Finally, Iceberg provides a transactional and scalable table format to efficiently manage and govern the data within the data lake.
With this architecture, organizations can implement end-to-end streaming data pipelines, from data ingestion to processing and storage. Real-time data can be ingested into Kafka, processed using Flink's powerful stream processing capabilities, and stored efficiently using Iceberg's table format. This foundation enables organizations to build real-time analytics, machine learning, and other data-driven applications on top of their streaming data lakes.
We can start up our streaming data lakehouse stack by running the following command:
docker-compose upNow, when every service is ready, head over to the Jupyter Notebook interface, and create a test database.
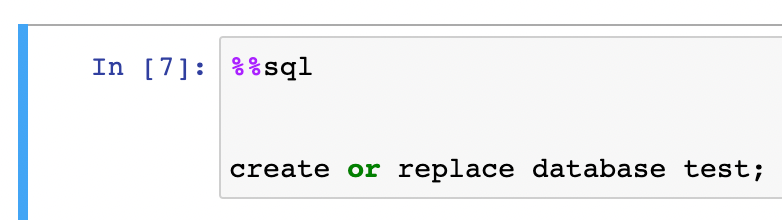
After the database is created, we can submit our Flink job! First, let's build it.
./gradlew clean shadowJarThen head over to the Flink UI at http://localhost:8081/#/submit and submit the .jar archive we build in the previous step.
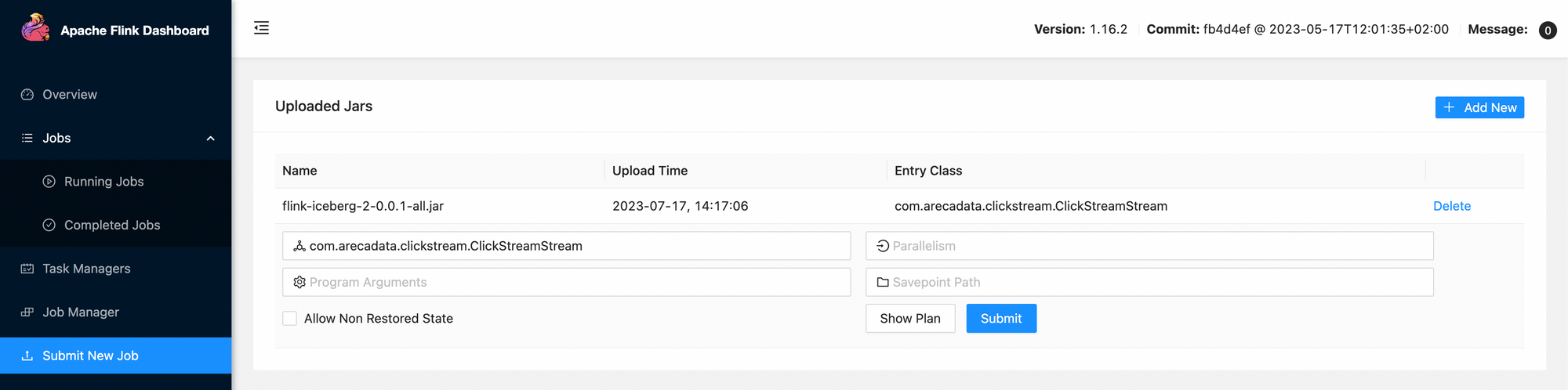
Press submit to deploy the code and head over back to the Notebook to quickly verify the results!
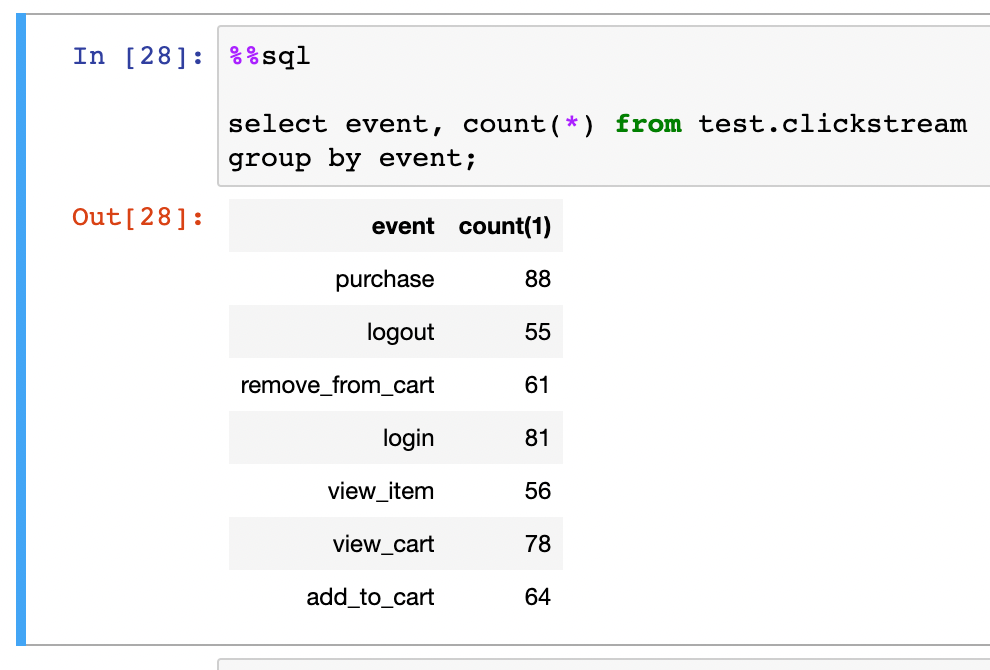
Nice! We have an end-to-end pipeline pushing data into Kafka, transforming it in Flink, and finally, sinking everything into an Iceberg table!
The whole example code is available on GitHub.
Conclusion
Streaming data lakes have become a critical component for organizations dealing with large volumes of real-time data. Kafka, Flink, and Iceberg provide the foundational technologies required to build scalable, fault-tolerant, and efficient streaming data lake infrastructures.
By leveraging Kafka's data ingestion capabilities, Flink's stream processing capabilities, and Iceberg's scalable table format, organizations can derive valuable insights and build powerful applications on top of their streaming data lakes. With these technologies, organizations can unlock the true potential of their data and drive data-driven decision-making.
Member discussion