Temporal analysis of Wikipedia changes with Redpanda & Materialize & dbt

The source
I have recently discovered that Wikimedia (The organization behind Wikipedia) has a publicly available streaming API for all Mediawiki sites (wikidata, wikipedia, etc.), called the EventStreams, which uses the Server-Sent Events protocol and is backed by Kafka internally.
EventStreams provides access to several different data streams, most notably the recentchange stream which emits MediaWiki Recent changes events.
All code for this project is available in this repository.
High-level architecture
In order to get the data into Materialize, first, we will consume the EventStreams API with Python and push the records into Redpanda, which can be set up as a Source in Materialize, from where using Websockets we can display it in a basic website.
Ingestion
I wrote a small Python script to load our data into Redpanda (Kafka-compatible storage).
To start our Redpanda cluster all we have to do is runrpk container start -n 3
Which will download and start a 3-node Redpanda Docker container. After the cluster is up you should see something likeStarting cluster
Waiting for the cluster to be ready...
NODE ID ADDRESS
0 127.0.0.1:63248
1 127.0.0.1:63249
2 127.0.0.1:63250Cluster started! You may use rpk to interact with it. E.g:rpk cluster info
To create our Topic for loading the event changes into run:rpk topic create recentchange --brokers 127.0.0.1:63248,127.0.0.1:63249,127.0.0.1:63250
And that’s it!
The data
For this project, we will only use the recentchange API which is available at the URL https://stream.wikimedia.org/v2/stream/recentchange. A sample event change record looks like this:{
"$schema":"/mediawiki/recentchange/1.0.0",
"meta":{
"uri":"https://commons.wikimedia.org/wiki/Category:Mammals_in_Murchison_Falls_National_Park",
"request_id":"c216f49d-73f1-4795-82f2-83a5af0acb2e",
"id":"757e2aa4-3c32-45d1-b447-d1cf68c007f0",
"dt":"2022-06-27T06:55:35Z",
"domain":"commons.wikimedia.org",
"stream":"mediawiki.recentchange",
"topic":"eqiad.mediawiki.recentchange",
"partition":0,
"offset":3965649732
},
"id":1957537662,
"type":"categorize",
"namespace":14,
"title":"Category:Mammals in Murchison Falls National Park",
"comment":"[[:File:A Pair of Harte Beests (Antelope Family) in the grasslands of Murchision Falls National Park.jpg]] added to category",
"timestamp":1656312935,
"user":"Kilom691",
"bot":false,
"server_url":"https://commons.wikimedia.org",
"server_name":"commons.wikimedia.org",
"server_script_path":"/w",
"wiki":"commonswiki",
"parsedcomment":"<a href=\"/wiki/File:A_Pair_of_Harte_Beests_(Antelope_Family)_in_the_grasslands_of_Murchision_Falls_National_Park.jpg\" title=\"File:A Pair of Harte Beests (Antelope Family) in the grasslands of Murchision Falls National Park.jpg\">File:A Pair of Harte Beests (Antelope Family) in the grasslands of Murchision Falls National Park.jpg</a> added to category"
}
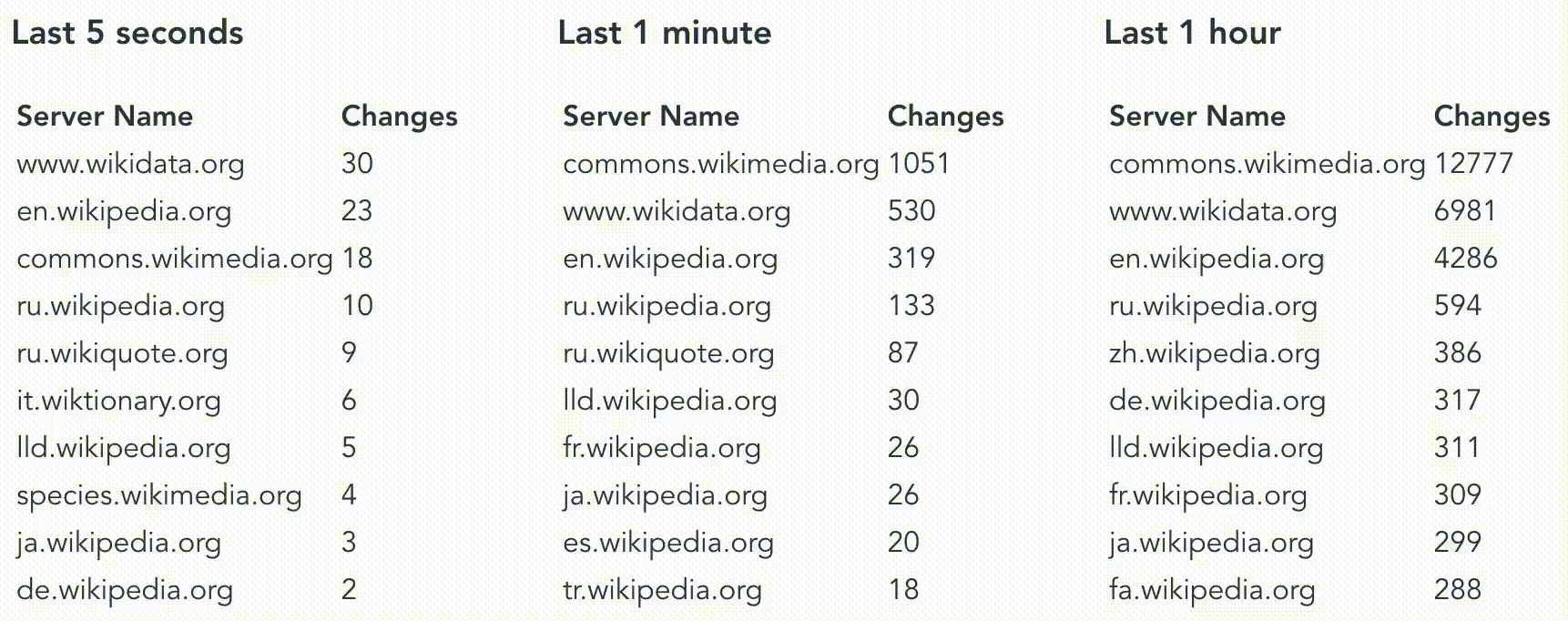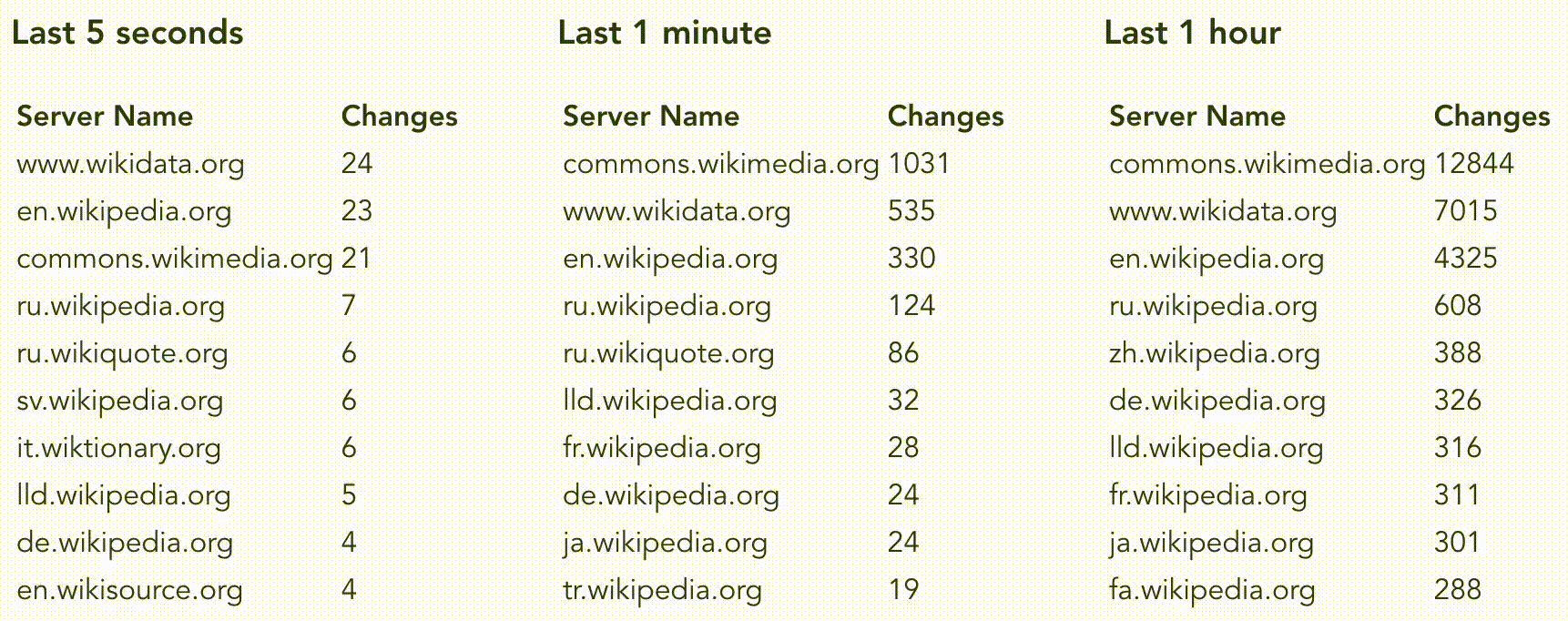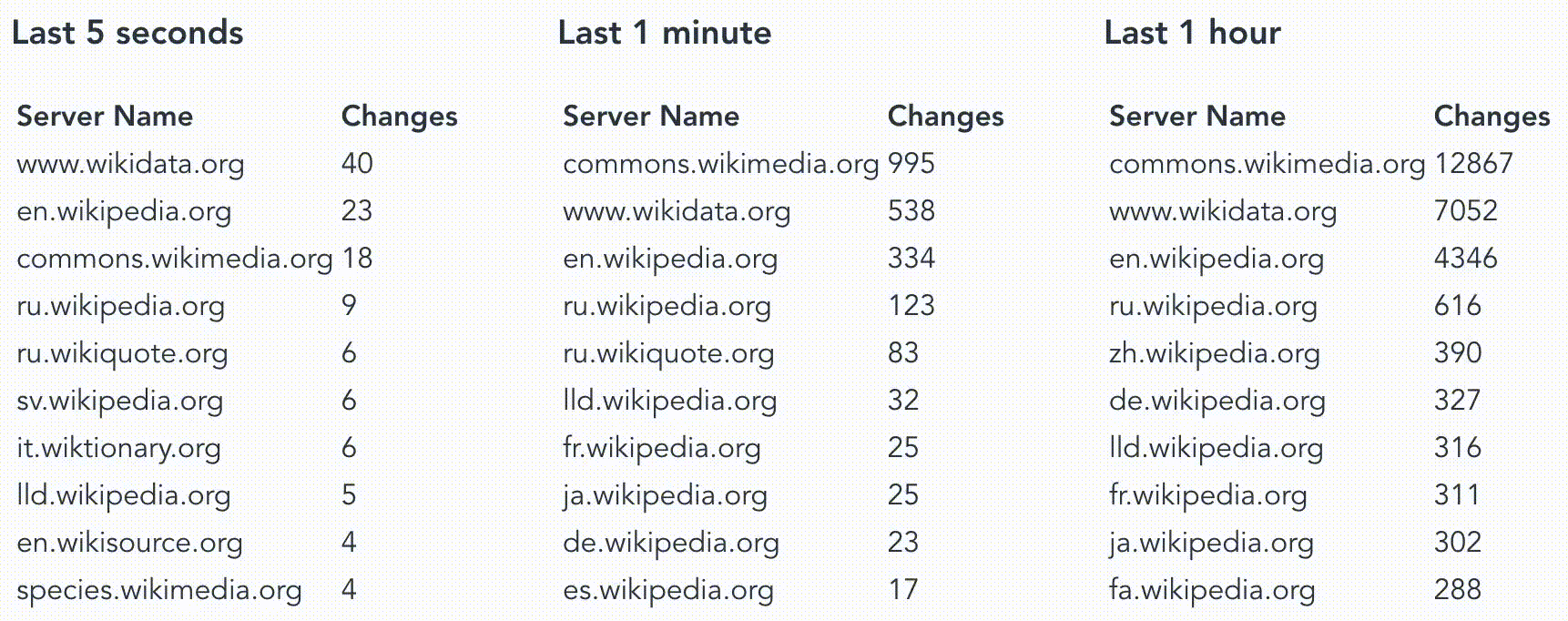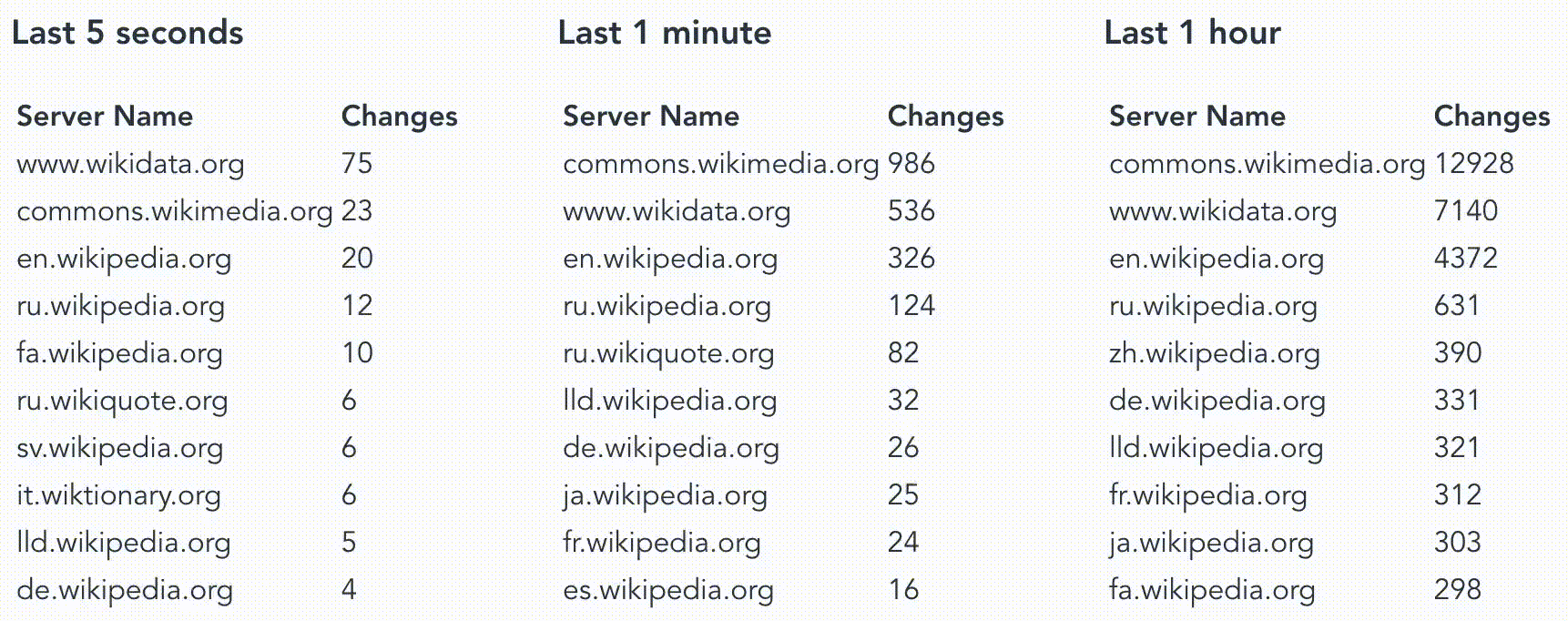
Our goal today is to explore how temporal filter work in Materialize and for this, we’ll want to answer questions like “How many changes have been made in the last hour/minute/second on a wiki site”? There are tons of interesting fields here that could be used to answer other questions but for now, we’ll focus on timestamp and server_name.
Transformation
With our data being consistently pushed into a Redpanda topic we can set up our next step, Materalize. All of the transformation steps will be defined via dbt to make our lives easier when trying to reproduce the pipeline.
The first thing we will have to do is create a Source object.{% set source_name %}
{{ mz_generate_name('src_wikidata_events') }}
{% endset %}
CREATE SOURCE {{ source_name }}
FROM KAFKA BROKER 'localhost:63248' TOPIC 'recentchange'
KEY FORMAT BYTES
VALUE FORMAT BYTES
ENVELOPE NONE
A source describes an external system you want Materialize to read data from, and provides details about how to decode and interpret that data. In this case our source is a Redpanda topic called recentchange and the format of both incoming keys and values will be rawBYTES which we will parse downstream in a staging model like this:
Materialize cannot decode JSON directly from an external data source currently.
The above snippet creates a non-materialized view, which only provides an alias for the SELECT statement it includes.
Note that this is very different from Materialize’s main type of view, materialized views, which we will use in the next models.
Non-materialized views do not store the results of the query. Instead, they simply store the verbatim of the included SELECT. This means they take up very little memory, but also provide little benefit in reducing the latency and computation needed to answer queries.
Materialize!
With our cleaned-up data exposed via a non-materialized view in place, we can create our “reporting” models where we answer our initial business question.
How many changes have been made in the last hour on every wiki site?
To answer this we will use a temporal filter.
Temporal filters allow you to implement several windowing idioms (tumbling, hopping, and sliding), in addition to more nuanced temporal queries.
A “temporal filter” is a WHERE or HAVING clause which uses the function mz_logical_timestamp to represent the current time through which your data is viewed.
The models' configuration will tell Materialize that this is a materialized view, which allows us to use the filter. This model is based on the sliding window pattern. Sliding windows are windows whose period approaches the limit of 0. This creates fixed-size windows that appear to slide continuously forward in time.
I have also created two other similar models with temporal filters for the past 5 seconds and 1 minute.
Visualize
To visualize the three models side by side I created a small FastAPI app, which reads the latest state via TAIL, which is a Materialize statement that streams updates. The API then pushes the records via Websockets to a Vue app which displays them as basic tables.
The interesting part of the API looks like this.
you can see that we create a Cursor for our TAIL statement and start fetching all data available.
And using my professional data visualization skill we end up with something like this.
I can highly recommend Materialize if you want to dabble with streaming analytics, it’s dead easy to spin up an instance and get started. In the repository, I included a docker-compose.yml which creates all the services used in the demo.
Member discussion